Read our latest LLM Hallucination Index: RAG Special
Galileo Luna: Breakthrough in LLM Evaluation, Beating GPT-3.5 and RAGAS




RAG systems often face the challenge of detecting and mitigating hallucinations—instances where the model generates information not grounded in the retrieved context. Ensuring the reliability and accuracy of responses generated by LLMs is crucial across diverse industry settings. Current hallucination detection techniques struggle to balance accuracy, low latency, and cost. Enter Galileo Luna – a family of Evaluation Foundation Models (EFM) fine-tuned specifically for hallucination detection in RAG settings. Luna not only outperforms GPT-3.5 and commercial evaluation frameworks but also significantly reduces cost and latency, making it an ideal candidate for industry LLM applications.
Performance Results
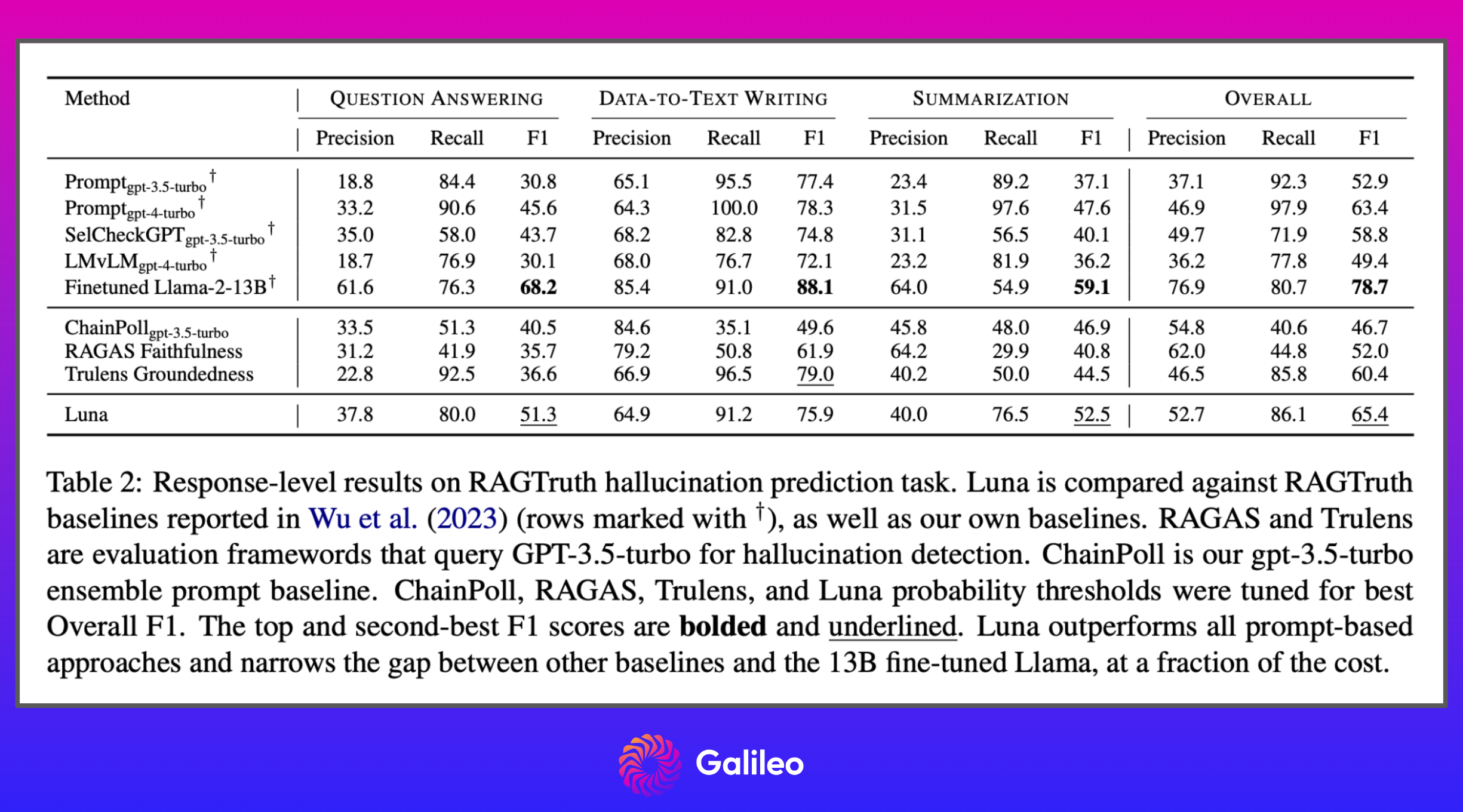
Luna excels on the RAGTruth dataset and shows excellent generalization capabilities. Luna's lightweight nature, combined with significant gains in cost and inference speed, makes it a highly efficient solution for industry applications.
Performance: Luna outperforms prompt-based methods like RAGAS & GPT3.5 on RAGTruth dataset in QA and Summarization tasks and is competitive in Data-to-Text Writing tasks.

Generalization: Luna outperforms RAGAS & GPT3.5 across different industry verticals.


Cost and Latency: Luna achieves a 97% reduction in cost and a 96% reduction in latency compared to GPT-3.5-based approaches.


We have shared more details about Luna in our launch blog.
Why Luna?
For RAG specifically, several evaluation frameworks such as RAGAS, Trulens, and ARES have been developed to automate hallucination detection on a large scale. However, these methods often rely on static LLM prompts or fine-tuning on specific in-domain data, which limits their ability to generalize across various industry applications.
Customer-facing dialogue systems require a hallucination detection solution that is highly accurate, quick, and cost-effective to ensure that hallucinations are identified and corrected before reaching the user. Current LLM prompt-based methods fall short of meeting the stringent latency requirements due to their model size.
Furthermore, while commercial LLMs like OpenAI's GPT models perform well, querying customer data through third-party APIs is expensive and raises privacy and security concerns. Fine-tuned BERT-sized models can offer competitive performance with lower latency and the ability to run locally, but they need annotated data for fine-tuning and have not been tested extensively for large-scale, cross-domain applications.
Our EFM research paper presents Luna, a lightweight RAG hallucination detection model capable of generalizing across multiple industry domains and scaling efficiently for real-time deployment. Luna is a DeBERTa-large encoder, fine-tuned on a meticulously curated dataset of real-world RAG scenarios.
By analyzing RAG in production environments, we identified long-context RAG evaluation as an unaddressed challenge and developed a novel solution for high-precision, long-context hallucination detection. Through extensive benchmarking, we show that Luna outperforms zero-shot prompting and existing RAG evaluation frameworks in hallucination detection tasks.
We evaluated two commercial RAG evaluation frameworks: RAGAS and Trulens, focusing on their Faithfulness and Groundedness metrics designed for hallucination detection.
Evaluation Dataset
RAG QA Dataset
To simulate natural RAG examples in production settings, we constructed a RAG QA dataset by recycling open-book QA datasets. The combined dataset features a diverse range of challenging RAG task types, such as numerical reasoning over tables, inference across multiple context documents, and retrieval from extensive contexts. We allocate 20% of the dataset for validation and testing purposes.
Customer Support
- DelucionQA (Sadat et al., 2023)
- EManual (Nandy et al., 2021)
- TechQA (Castelli et al., 2020)
Finance and Numerical Reasoning
- FinQA (Chen et al., 2021)
- TAT-QA (Zhu et al., 2021)
Biomedical Research
- PubmedQA (Jin et al., 2019)
- CovidQA (Möller et al., 2020)
Legal
- Cuad (Hendrycks et al., 2021)
General Knowledge
- HotpotQA (Yang et al., 2018)
- MS Marco (Nguyen et al., 2016)
- HAGRID (Kamalloo et al., 2023)
- ExpertQA (Malaviya et al., 2024)
We disregard the original responses for each subset of the dataset and generate two new responses per input using GPT-3.5 and Claude-3-Haiku. These models are chosen for their strong reasoning, conversational skills, and cost-effectiveness, making them viable options for production RAG systems. We set the generation temperature to 1 to promote diversity and the possibility of hallucinations in the responses.
RAGTruth
RAGTruth is a meticulously curated collection of 18,000 RAG examples, featuring responses generated by large language models. This dataset is divided into three distinct RAG task categories: Question Answering (QA), Data-to-text Writing, and News Summarization.
Although Luna is exclusively trained on QA RAG examples, we utilize this benchmark to assess our model's ability to generalize across the other RAG task categories.
Evaluation Methodology
Labeling process
We used GPT-4-turbo to annotate the RAG QA dataset. The context and response were split into sentences, and the LLM was instructed to identify which context sentences supported the claims in the response. Unsupported tokens were treated as hallucinations. We ensured high-quality labels through multiple re-annotations and manual inspections.
Zero-shot Prompting
We evaluated GPT-3.5-turbo and GPT-4-turbo models as baselines, prompting them to return a boolean indicating whether a RAG response was supported by the associated context. For RAGTruth, we reported the best Precision, Recall, and F1 scores, tuning model output probability thresholds for optimal performance.
Innovations in Luna


Intelligent Chunking Approach
We employ a dynamic windowing technique that separately splits both the input context and the response, ensuring comprehensive validation and significantly improving hallucination detection accuracy.
Multi-task Training
Luna EFMs conduct multiple evaluations using a single input, thanks to multi-task training. This allows EFMs to share insights and predictions, leading to more robust and accurate evaluations.
Data Augmentation
Each Luna EFM is trained on large, high-quality datasets spanning various industries and use cases. We enrich our training dataset with synthetic data and data augmentations to improve domain coverage and generalization.
Token Level Evaluation


Our model classifies each sentence as adherent or non-adherent by comparing it against every piece of the context. This granularity enhances transparency and the utility of model outputs, making debugging easier.
Latency Optimizations
Luna is optimized to process up to 16k input tokens in under one second on an NVIDIA L4 GPU. This is achieved through deploying an ONNX-traced model on an NVIDIA Triton server with a TensorRT backend, leveraging Triton’s Business Logic Scripting (BLS) for efficient resource allocation.
Long Context Support
Luna effectively detects hallucinations in long RAG contexts. Luna is optimized to process up to 16,000 tokens within milliseconds on cost general-purpose GPUs.
What customers are saying
"Evaluations are absolutely essential to delivering safe, reliable, production-grade AI products," said Alex Klug, Head of Product, Data Science & AI at HP.
Until now, existing evaluation methods, such as human evaluations or using LLMs as a judge, have been very costly and slow.
With Luna®, Galileo is overcoming enterprise teams' biggest evaluation hurdles – cost, latency, and accuracy. This is a game changer for the industry.
Conclusion
Luna represents a significant advancement in hallucination detection for RAG systems. Its exceptional performance and cost-efficiency make it an ideal solution for enterprise applications. With innovations in model architecture, Luna sets a new standard for reliability in RAG evaluations. Get started with Luna today!


To learn more about the Luna family of Evaluation Foundation Models and see them in action, join us on June 18th for a live webinar or contact us for further information.
Subscribe to Newsletter
Working with Natural Language Processing?
Read about Galileo’s NLP Studio
