Model Insights
mixtral-8x22b-instruct-v0.1
Details
Developer
mistral
License
Apache 2.0
Model parameters
176b
Supported context length
64k
Price for prompt token
$1.2/Million tokens
Price for response token
$1.2/Million tokens
Model Performance Across Task-Types
Chainpoll Score
Short Context
0.93
Medium Context
0.99
Model Insights Across Task-Types
Digging deeper, here’s a look how mixtral-8x22b-instruct-v0.1 performed across specific datasets
Short Context RAG
Medium Context RAG
This heatmap indicates the model's success in recalling information at different locations in the context. Green signifies success, while red indicates failure.
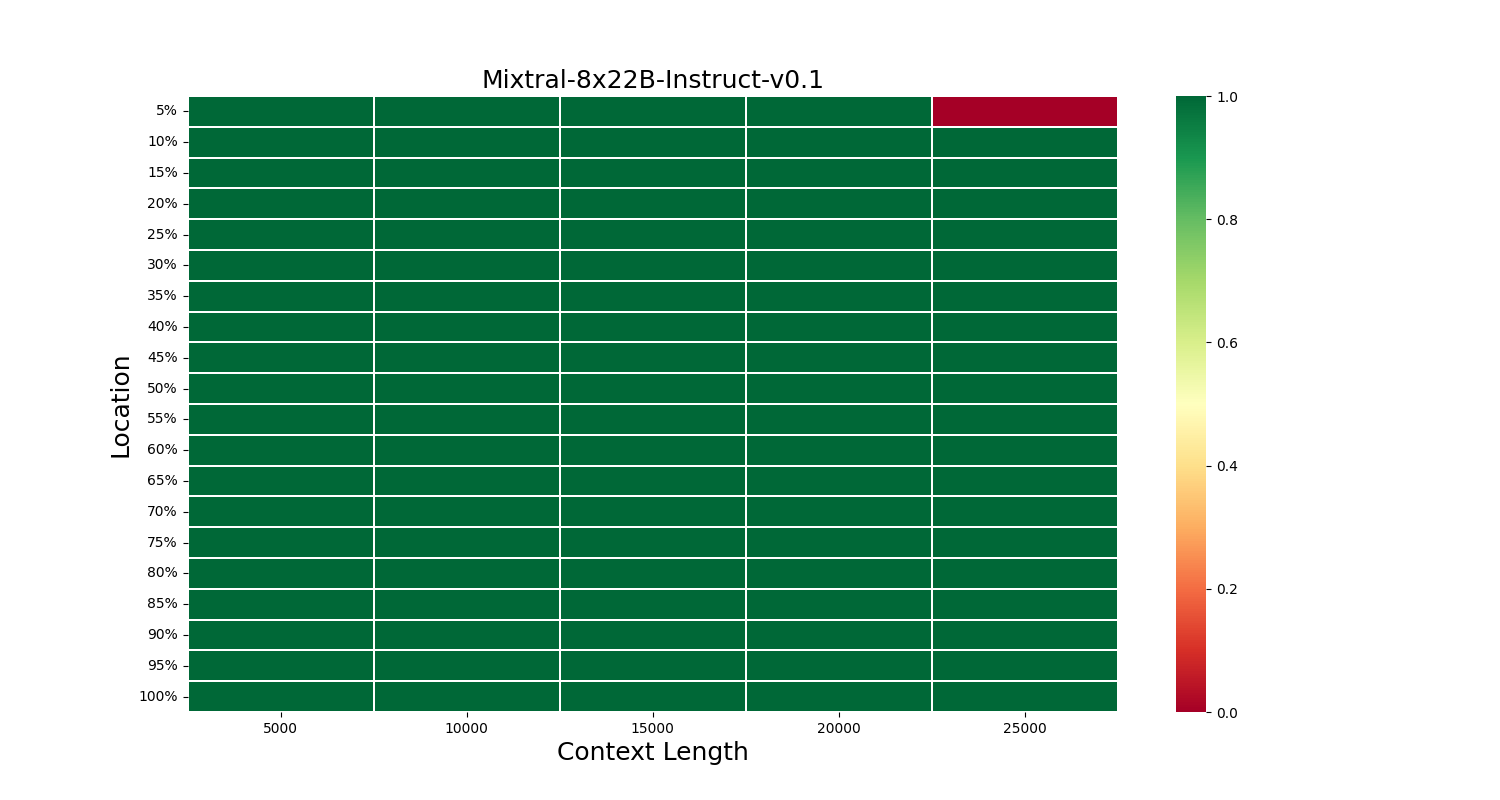
Performance Summary
| Tasks | Task insight | Cost insight | Dataset | Context adherence | Avg response length |
|---|---|---|---|---|---|
| Short context RAG | The model demonstrates exceptional reasoning and comprehension skills, excelling at short context RAG. It shows good mathematical proficiency, as evidenced by its performance on DROP and ConvFinQA benchmarks. | It is a great open source model but 15x costlier than Gemini Flash with similar performance. We do not recommend using this. | Drop | 0.93 | 368 |
| Hotpot | 0.89 | 368 | |||
| MS Marco | 0.94 | 368 | |||
| ConvFinQA | 0.96 | 368 | |||
| Medium context RAG | Flawless performance making it suitable for any context length upto 20000 tokens. It struggles a bit for 25000 but can be used without much issues. | Great performance but we recommed using 12x cheaper Gemini Flash. | Medium context RAG | 0.99 | 368 |